Spring - Bases de datos relacionales
🗄️ Spring Data
Objetivo: Dominar el acceso a datos en Spring desde sus fundamentos hasta técnicas avanzadas. Entender qué herramienta usar en cada situación y por qué.
Prerrequisitos: Conocimiento básico de Spring Boot, Java, y SQL.
📌 ÍNDICE
Parte 1 — Fundamentos
- El problema del acceso a datos en Java
- El ecosistema Spring Data
- Spring Data JDBC vs Spring Data JPA
- Conectores y Dependencias
- Configuración de la Base de Datos
Parte 2 — JPA y Entidades
- JPA: Mapeo de Entidades (@Entity)
- Relaciones entre Entidades
- Herencia en JPA
Parte 3 — Repositorios y Consultas
- Repositorios Spring Data
- Derived Query Methods
- @Query — JPQL y HQL
- @Query NativeQuery — SQL puro
- Projections — Traer solo lo que necesitas
- Paginación y Ordenamiento
- Specifications — Consultas dinámicas
- QueryDSL
- Spring Data JDBC en detalle
- JdbcTemplate — SQL directo
- Transacciones en Spring Data
- Auditoría automática
1. FUNDAMENTOS
El problema del acceso a datos en Java
Antes de Spring Data: JDBC puro
Para entender el valor de Spring Data, hay que ver cómo se hacía sin él
// JDBC puro — lo que había antes (y sigue existiendo pero spring lo abstrae)
public class ProductoDAO {
public Producto buscarPorId(Long id) {
String sql = "SELECT id, nombre, precio, stock FROM productos WHERE id = ?";
Connection conn = null;
PreparedStatement stmt = null;
ResultSet rs = null;
try {
// 1. Obtener conexión del DriverManager
conn = DriverManager.getConnection(
"jdbc:mysql://localhost:3306/tienda", "root", "secret");
// 2. Preparar el statement
stmt = conn.prepareStatement(sql);
stmt.setLong(1, id);
// 3. Ejecutar
rs = stmt.executeQuery();
// 4. Mapear resultado fila → objeto
if (rs.next()) {
Producto p = new Producto();
p.setId(rs.getLong("id"));
p.setNombre(rs.getString("nombre"));
p.setPrecio(rs.getBigDecimal("precio"));
p.setStock(rs.getInt("stock"));
return p;
}
return null;
} catch (SQLException e) {
throw new RuntimeException("Error al buscar producto", e);
} finally {
// 5. Cerrar recursos (obligatorio, o memory/connection leak)
try { if (rs != null) rs.close(); } catch (SQLException e) { /* ignorar */ }
try { if (stmt != null) stmt.close(); } catch (SQLException e) { /* ignorar */ }
try { if (conn != null) conn.close(); } catch (SQLException e) { /* ignorar */ }
}
}
// Costoso tanto en código como en rendimiento
}Los problemas de JDBC puro
Boilerplate masivo: try-catch-finally idéntico en cada método
Gestión manual de conexiones: fácil causar connection leaks
Mapeo manual: ResultSet → objeto, campo por campo
Sin pool de conexiones: crear/destruir conexiones es muy costoso
Sin gestión de transacciones automática
SQL mezclado con código Java: difícil de mantener
Sin detección de errores en tiempo de compilación
La solución: Spring Data
// Con Spring Data JPA — el mismo comportamiento
public interface ProductoRepository extends JpaRepository<Producto, Long> {
// Spring genera la implementación completa automáticamente
// findById(id) ya existe, es una consulta generica por asi decirlo: hereda de JpaRepository
// Nada de código, spring se encarga de la implementación
}
// Uso en servicio:
Optional<Producto> producto = repo.findById(1L);2. El ecosistema Spring Data
Spring Data es un proyecto abstracto que contiene múltiples módulos para diferentes tecnologías de persistencia. Todos comparten la misma abstracción de repositorio pero se adaptan a cada tecnología.
Spring Data
├── Spring Data Commons ← abstracción base (Repository, CrudRepository, etc.)
│
├── Bases de datos relacionales:
│ ├── Spring Data JPA ← JPA/Hibernate, lo mas usado
│ ├── Spring Data JDBC ← JDBC simple, como antes pero no tan complejo
│ └── Spring Data R2DBC ← JDBC reactivo (non-blocking)
│
├── Bases de datos NoSQL:
│ ├── Spring Data MongoDB ← MongoDB
│ ├── Spring Data Redis ← Redis (caché, sesiones)
│ ├── Spring Data Cassandra ← Apache Cassandra
│ ├── Spring Data Elasticsearch ← Elasticsearch
│ └── Spring Data Neo4j ← Base de datos de grafos
│
└── Otros:
├── Spring Data REST ← expone repositorios como API REST automáticamente
└── Spring Data KeyValue ← abstracción para Map-based stores
La jerarquía de repositorios
// La jerarquía de repositorios y abstracciones
// 1. Repository<T, ID> — interfaz marcadora, sin métodos (base de todo)
public interface Repository<T, ID> {}
// 2. CrudRepository<T, ID> — operaciones CRUD básicas
public interface CrudRepository<T, ID> extends Repository<T, ID> {
<S extends T> S save(S entity);
<S extends T> Iterable<S> saveAll(Iterable<S> entities);
Optional<T> findById(ID id);
boolean existsById(ID id);
Iterable<T> findAll();
Iterable<T> findAllById(Iterable<ID> ids);
long count();
void deleteById(ID id);
void delete(T entity);
void deleteAll();
}
// 3. PagingAndSortingRepository<T, ID> — agrega paginación y ordenamiento
public interface PagingAndSortingRepository<T, ID> extends CrudRepository<T, ID> {
Iterable<T> findAll(Sort sort);
Page<T> findAll(Pageable pageable);
}
// 4. JpaRepository<T, ID> — agrega métodos específicos de JPA
public interface JpaRepository<T, ID> extends PagingAndSortingRepository<T, ID> {
void flush();
<S extends T> S saveAndFlush(S entity);
void deleteInBatch(Iterable<T> entities);
List<T> findAll();
List<T> findAll(Sort sort);
List<T> findAllById(Iterable<ID> ids);
// ... más métodos JPA-específicos
}
// Nuestros repositorios extiende el nivel que se necesitan:
// Solo CRUD básico:
public interface ProductoRepository extends CrudRepository<Producto, Long> {}
// Con paginación:
public interface ProductoRepository extends PagingAndSortingRepository<Producto, Long> {}
// Con todo (lo más común):
public interface ProductoRepository extends JpaRepository<Producto, Long> {}3. Spring Data JDBC vs Spring Data JPA
No son lo mismo pero el propósito si
| Spring Data JDBC | Spring Data JPA | |
|---|---|---|
| Abstracción | SQL directo | ORM (Mapeo objeto- relacional) |
| Lazy Loading | No existe | Sí, @OneToMany es Lazy |
| Caché de primer nivel | No | Sí (Session cache) |
| Gestión de estado | Objetos simples | Entidades son manejadas por JPA |
| Relaciones | Agregados explícitos (DDD) | Transparentes con anotaciones |
| SQL generado | Simple | Complejo |
| Performance | Predecible | Puede generar problemas N+1 |
| Casos de uso | Apps simples, DDD, microservicios | Apps complejas con muchas relaciones |
| Cuando elegir | Se requiere control minucioso | Queremos que el ORM haga todo |
4. Conectores y Dependencias
Dependencias Maven por base de datos
<!-- pom.xml — elige las dependencias según la base de datos-->
<!-- SPRING DATA JPA (base para JPA/Hibernate) -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
<!-- Incluye: spring-data-jpa, hibernate-core, spring-jdbc, spring-tx -->
</dependency>
<!-- SPRING DATA JDBC (alternativa simple) -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jdbc</artifactId>
</dependency>
<!-- CONECTORES JDBC — eligir según la BD -->
<!-- MySQL -->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>
<!-- PostgreSQL -->
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<scope>runtime</scope>
</dependency>
<!-- Oracle (requiere licencia en repositorio privado) -->
<dependency>
<groupId>com.oracle.database.jdbc</groupId>
<artifactId>ojdbc11</artifactId>
<scope>runtime</scope>
</dependency>
<!-- SQL Server (Microsoft) -->
<dependency>
<groupId>com.microsoft.sqlserver</groupId>
<artifactId>mssql-jdbc</artifactId>
<scope>runtime</scope>
</dependency>
<!-- H2 (en memoria — perfecto para desarrollo y tests) -->
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
<!-- scope=runtime: solo para ejecutar, no para compilar -->
<!-- scope=test: solo en tests (lo más común) -->
</dependency>
<!-- MariaDB -->
<dependency>
<groupId>org.mariadb.jdbc</groupId>
<artifactId>mariadb-java-client</artifactId>
<scope>runtime</scope>
</dependency>
<!-- SQLite -->
<dependency>
<groupId>org.xerial</groupId>
<artifactId>sqlite-jdbc</artifactId>
<scope>runtime</scope>
</dependency>Dependencias para testing con BD real (Testcontainers)
<!-- Testcontainers: levanta una BD real en Docker para los tests -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-testcontainers</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.testcontainers</groupId>
<artifactId>mysql</artifactId> <!-- o postgresql, oracle, etc. -->
<scope>test</scope>
</dependency>5. Configuración de la Base de Datos
application.properties por base de datos
# H2 (en memoria — desarrollo rápido)
spring.datasource.url=jdbc:h2:mem:testdb;DB_CLOSE_DELAY=-1;DB_CLOSE_ON_EXIT=FALSE
spring.datasource.driver-class-name=org.h2.Driver
spring.datasource.username=sa
spring.datasource.password=
# Consola web de H2 (útil para debug)
spring.h2.console.enabled=true
spring.h2.console.path=/h2-console
# JPA
spring.jpa.database-platform=org.hibernate.dialect.H2Dialect
spring.jpa.hibernate.ddl-auto=create-drop
# H2 en archivo (persiste entre reinicios)
# spring.datasource.url=jdbc:h2:file:./datos/mibd
# MySQL
spring.datasource.url=jdbc:mysql://localhost:3306/tienda?useSSL=false&serverTimezone=UTC&allowPublicKeyRetrieval=true
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.username=root
spring.datasource.password=secret
# JPA
spring.jpa.database-platform=org.hibernate.dialect.MySQLDialect
spring.jpa.hibernate.ddl-auto=update
spring.jpa.show-sql=true
spring.jpa.properties.hibernate.format_sql=true
# PostgreSQL
spring.datasource.url=jdbc:postgresql://localhost:5432/tienda
spring.datasource.driver-class-name=org.postgresql.Driver
spring.datasource.username=postgres
spring.datasource.password=secret
# JPA
spring.jpa.database-platform=org.hibernate.dialect.PostgreSQLDialect
spring.jpa.hibernate.ddl-auto=validate
spring.jpa.show-sql=true
# Oracle
spring.datasource.url=jdbc:oracle:thin:@localhost:1521:XE
spring.datasource.driver-class-name=oracle.jdbc.OracleDriver
spring.datasource.username=system
spring.datasource.password=oracle
# JPA
spring.jpa.database-platform=org.hibernate.dialect.OracleDialect
spring.jpa.hibernate.ddl-auto=validate
# SQL Server
spring.datasource.url=jdbc:sqlserver://localhost:1433;databaseName=tienda;encrypt=false
spring.datasource.driver-class-name=com.microsoft.sqlserver.jdbc.SQLServerDriver
spring.datasource.username=sa
spring.datasource.password=YourStrong@Password
# JPA
spring.jpa.database-platform=org.hibernate.dialect.SQLServerDialect
spring.jpa.hibernate.ddl-auto=update
Configuración del Pool de Conexiones (HikariCP)
Spring Boot usa HikariCP por defecto — el pool de conexiones más rápido para Java
Un pool de conexiones permite gestionar multiples interacciones a la base de datos sin interrumpir otras conexiones, mejorando el performance de las aplicaciones
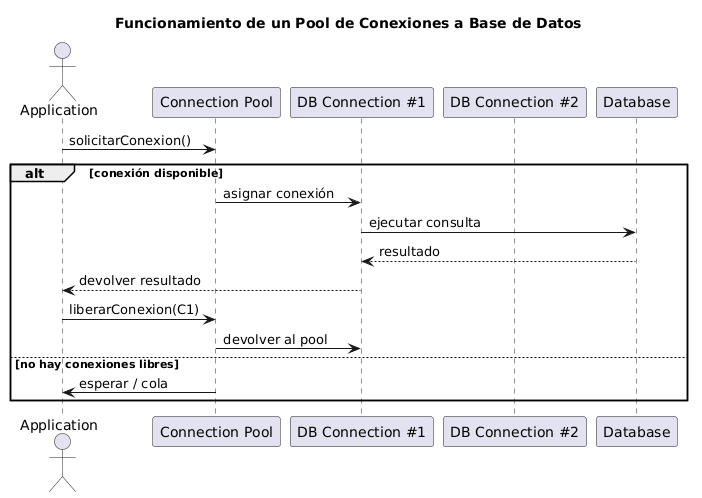
# HikariCP
# Máximo de conexiones activas simultáneamente
# Regla general: (núcleos_CPU * 2) + spindle_count
# Para app típica con 4 núcleos: 10
spring.datasource.hikari.maximum-pool-size=10
# Mínimo de conexiones siempre abiertas (idle)
spring.datasource.hikari.minimum-idle=5
# Tiempo máximo de espera para obtener una conexión (ms)
spring.datasource.hikari.connection-timeout=30000
# Tiempo máximo que una conexión puede estar ociosa antes de cerrarse (ms)
spring.datasource.hikari.idle-timeout=600000
# Tiempo máximo de vida de una conexión (ms) — para evitar conexiones "viejas"
spring.datasource.hikari.max-lifetime=1800000
# Nombre del pool (útil para monitoring)
spring.datasource.hikari.pool-name=MiAppPool
# Query de validación (se ejecuta al obtener una conexión para verificar que esté viva)
spring.datasource.hikari.connection-test-query=SELECT 1
# (para MySQL/PostgreSQL — para Oracle se usa: SELECT 1 FROM DUAL)
Valores de ddl-auto — ¿Cuál usar?
# spring.jpa.hibernate.ddl-auto tiene 5 valores:
# none → Hibernate no hace nada con el esquema
# PRODUCCIÓN (gestionar esquema con Flyway/Liquibase)
# validate → Verifica que el esquema coincide con las entidades, no modifica nada
# Lanza excepción si hay diferencias
# PRODUCCIÓN (si se gestiona el ddl manualmente)
# update → Agrega columnas/tablas faltantes, NO elimina nada
# DESARROLLO (cómodo pero peligroso en producción)
# NUNCA EN PRODUCCIÓN (puede dejar columnas huérfanas)
# create → Crea el esquema al iniciar (destruye datos existentes)
# TESTS o primera vez en desarrollo
# create-drop → create al iniciar, drop al cerrar la app
# TESTS con H2 en memoria
Configurar múltiples DataSources
// Cuando necesitas conectarte a dos bases de datos diferentes, es útil conocer
// como crear pools de conexiones
@Configuration
public class MultiDataSourceConfig {
// DataSource primario (default)
@Primary
@Bean("primaryDataSource")
@ConfigurationProperties("spring.datasource.primary")
public DataSource primaryDataSource() {
return DataSourceBuilder.create().build();
}
@Primary
@Bean("primaryEntityManagerFactory")
public LocalContainerEntityManagerFactoryBean primaryEntityManagerFactory(
@Qualifier("primaryDataSource") DataSource dataSource,
EntityManagerFactoryBuilder builder
) {
return builder
.dataSource(dataSource)
.packages("com.ejemplo.dominio.primario") // paquete de entidades
.persistenceUnit("primario")
.build();
}
// DataSource secundario
@Bean("secondaryDataSource")
@ConfigurationProperties("spring.datasource.secondary")
public DataSource secondaryDataSource() {
return DataSourceBuilder.create().build();
}
@Bean("secondaryEntityManagerFactory")
public LocalContainerEntityManagerFactoryBean secondaryEntityManagerFactory(
@Qualifier("secondaryDataSource") DataSource dataSource,
EntityManagerFactoryBuilder builder
) {
return builder
.dataSource(dataSource)
.packages("com.ejemplo.dominio.secundario")
.persistenceUnit("secundario")
.build();
}
}# application.properties para múltiples DataSources
spring.datasource.primary.url=jdbc:mysql://localhost:3306/tienda_principal
spring.datasource.primary.username=root
spring.datasource.primary.password=secret
spring.datasource.primary.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.secondary.url=jdbc:postgresql://localhost:5432/analytics
spring.datasource.secondary.username=postgres
spring.datasource.secondary.password=secret
spring.datasource.secondary.driver-class-name=org.postgresql.Driver
Gestión de esquema con Flyway
<!-- Para producción: usar Flyway en lugar de ddl-auto=update -->
<dependency>
<groupId>org.flywaydb</groupId>
<artifactId>flyway-core</artifactId>
</dependency>
<!-- Si se usa MySQL 8+: -->
<dependency>
<groupId>org.flywaydb</groupId>
<artifactId>flyway-mysql</artifactId>
</dependency>-- src/main/resources/db/migration/V1__crear_esquema_inicial.sql
CREATE TABLE categorias (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
nombre VARCHAR(100) NOT NULL,
descripcion TEXT
);
CREATE TABLE productos (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
nombre VARCHAR(200) NOT NULL,
precio DECIMAL(10,2) NOT NULL,
stock INT NOT NULL DEFAULT 0,
activo BOOLEAN NOT NULL DEFAULT TRUE,
categoria_id BIGINT,
FOREIGN KEY (categoria_id) REFERENCES categorias(id)
);-- src/main/resources/db/migration/V2__agregar_columna_descripcion.sql
ALTER TABLE productos ADD COLUMN descripcion TEXT;# application.properties
spring.flyway.enabled=true
spring.flyway.locations=classpath:db/migration
spring.flyway.baseline-on-migrate=true
# Deshabilitar ddl-auto cuando usas Flyway
spring.jpa.hibernate.ddl-auto=none
6. JPA Y ENTIDADES
¿Qué es JPA?
JPA (Java Persistence API) es una especificación de Java que define cómo mapear objetos Java a tablas de base de datos. Hibernate es la implementación más popular de JPA (y la que usa Spring Boot por defecto).
CLASE JAVA JPA/Hibernate BASE DE DATOS
───────────── ───────────── ─────────────
@Entity ↔ TABLE
campo id ↔ columna id (PK)
campo nombre ↔ columna nombre
@ManyToOne ↔ FOREIGN KEY
List<items> ↔ JOIN a otra tabla
Anotaciones básicas de entidad
// Entidad básica completa
@Entity // marca la clase como entidad JPA
@Table(
name = "productos", // nombre de la tabla (default: nombre clase en minúsculas)
schema = "tienda", // esquema opcional
indexes = { // índices de BD
@Index(name = "idx_nombre", columnList = "nombre"),
@Index(name = "idx_precio_activo", columnList = "precio, activo")
},
uniqueConstraints = { // restricciones de bd
@UniqueConstraint(name = "uk_nombre", columnNames = {"nombre"})
}
)
public class Producto {
// Clave primaria
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
// IDENTITY: autoincrement de la BD (MySQL, PostgreSQL, SQL Server)
// SEQUENCE: secuencia de BD (Oracle, PostgreSQL)
// AUTO: Spring elige la estrategia (no recomendado en produccion)
// TABLE: tabla generadora de IDs (lento, tambien evitar)
@Column(name = "id")
private Long id;
// Columnas básicas
@Column(
name = "nombre", // nombre de columna (default: nombre del campo)
nullable = false, // NOT NULL en BD
length = 200, // VARCHAR(200)
unique = false
)
private String nombre;
@Column(nullable = false, precision = 10, scale = 2)
// precision = total de dígitos, scale = decimales
// DECIMAL(10,2) en BD
private BigDecimal precio;
@Column(columnDefinition = "TEXT") // tipo SQL directo
private String descripcion;
@Column(name = "esta_activo", columnDefinition = "BOOLEAN DEFAULT TRUE")
private boolean activo = true;
// Fechas
@Column(name = "fecha_creacion", updatable = false)
// updatable = false: nunca se actualiza después de la inserción
private LocalDateTime fechaCreacion;
@Column(name = "fecha_actualizacion")
private LocalDateTime fechaActualizacion;
// Enumerados
@Enumerated(EnumType.STRING) // guarda "ACTIVO", "INACTIVO" en BD
// EnumType.ORDINAL guarda 0, 1, 2 (fragil ya que depende el orden del enum)
@Column(length = 20)
private EstadoProducto estado;
// Campos no persistidos
@Transient // este campo NO se guarda en BD
private String descripcionFormateada;
// Campos con tipo personalizado
@Convert(converter = ListaStringConverter.class)
@Column(name = "etiquetas")
private List<String> etiquetas;
// getters, setters, constructores...
}
// Enum del dominio
public enum EstadoProducto {
BORRADOR, ACTIVO, AGOTADO, DESCONTINUADO
}Estrategias de generación de ID
// IDENTITY — autoincrement de la BD (el más común)
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
// MySQL: AUTO_INCREMENT, PostgreSQL: SERIAL, SQL Server: IDENTITY
// SEQUENCE — secuencia de BD (recomendado para PostgreSQL/Oracle)
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "producto_seq")
@SequenceGenerator(
name = "producto_seq",
sequenceName = "seq_productos", // nombre en la BD
allocationSize = 50 // pre-asignar 50 IDs (reduce roundtrips a BD)
)
private Long id;
// UUID — identificador universal único
@Id
@GeneratedValue(strategy = GenerationType.UUID) // Spring Boot 3 / Hibernate 6
private UUID id;
// O asignado manualmente:
@Id
@Column(length = 36)
private String id;
@PrePersist
protected void asignarId() {
if (this.id == null) {
this.id = UUID.randomUUID().toString();
}
}Converters (@Converter)
// Convertir tipos Java ↔ tipos de BD que JPA no soporta nativamente
// Lista de Strings ↔ String separado por comas en BD
@Converter
public class ListaStringConverter implements AttributeConverter<List<String>, String> {
@Override
public String convertToDatabaseColumn(List<String> lista) {
if (lista == null || lista.isEmpty()) return "";
return String.join(",", lista);
// ["java", "spring", "jpa"] → "java,spring,jpa"
}
@Override
public List<String> convertToEntityAttribute(String valor) {
if (valor == null || valor.isBlank()) return new ArrayList<>();
return Arrays.asList(valor.split(","));
// "java,spring,jpa" → ["java", "spring", "jpa"]
}
}
// Objeto complejo ↔ JSON en BD
@Converter
public class DireccionJsonConverter implements AttributeConverter<Direccion, String> {
private static final ObjectMapper mapper = new ObjectMapper();
@Override
public String convertToDatabaseColumn(Direccion direccion) {
try {
return mapper.writeValueAsString(direccion);
} catch (JsonProcessingException e) {
throw new IllegalArgumentException("Error al serializar dirección", e);
}
}
@Override
public Direccion convertToEntityAttribute(String json) {
try {
return mapper.readValue(json, Direccion.class);
} catch (JsonProcessingException e) {
throw new IllegalArgumentException("Error al deserializar dirección", e);
}
}
}
// Uso en entidad:
@Entity
public class Usuario {
@Convert(converter = DireccionJsonConverter.class)
@Column(columnDefinition = "JSON") // MySQL 5.7+ / PostgreSQL soportan JSON nativo
private Direccion direccionPrincipal;
}7. Relaciones entre Entidades
@ManyToOne y @OneToMany
// Relación: Producto pertenece a una Categoría
// Una Categoría tiene muchos Productos
// Un Producto tiene una Categoría
@Entity
@Table(name = "categorias")
public class Categoria {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false, unique = true)
private String nombre;
// "Uno a muchos": una categoría tiene muchos productos
// mappedBy = nombre del campo en la entidad "muchos" que apunta a "uno"
@OneToMany(
mappedBy = "categoria", // campo en Producto que mapea esta relación
fetch = FetchType.LAZY, // LAZY (default): cargar productos solo cuando se acceda
cascade = CascadeType.ALL, // operaciones que se propagan a los productos
orphanRemoval = true // si un producto se quita de la lista → se elimina de BD
)
private List<Producto> productos = new ArrayList<>();
// Métodos helper para mantener la consistencia bidireccional
public void agregarProducto(Producto p) {
productos.add(p);
p.setCategoria(this);
}
public void quitarProducto(Producto p) {
productos.remove(p);
p.setCategoria(null);
}
}
@Entity
@Table(name = "productos")
public class Producto {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String nombre;
private BigDecimal precio;
// "Muchos a uno": muchos productos pertenecen a una categoría
@ManyToOne(
fetch = FetchType.LAZY, // LAZY: no cargar la categoría hasta que se acceda
optional = false // NOT NULL — el producto siempre debe tener categoría
)
@JoinColumn(
name = "categoria_id", // nombre de la FK en la tabla productos
nullable = false
)
private Categoria categoria;
}@OneToOne
@Entity
public class Usuario {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String email;
// Relación 1:1 con Perfil
@OneToOne(
mappedBy = "usuario", // campo en Perfil que tiene la FK
cascade = CascadeType.ALL,
fetch = FetchType.LAZY,
optional = true
)
private Perfil perfil;
}
@Entity
public class Perfil {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String bio;
private String urlFoto;
@OneToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "usuario_id", unique = true) // FK en la tabla perfil
private Usuario usuario;
}@ManyToMany
// Relación N:M: un Producto puede tener muchas Etiquetas
// Una Etiqueta puede pertenecer a muchos Productos
// Necesita tabla intermedia: producto_etiqueta
@Entity
public class Producto {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@ManyToMany(
fetch = FetchType.LAZY,
cascade = {CascadeType.PERSIST, CascadeType.MERGE}
// NUNCA CascadeType.ALL en ManyToMany — podría eliminar etiquetas compartidas
)
@JoinTable(
name = "producto_etiqueta", // tabla intermedia
joinColumns = @JoinColumn(name = "producto_id"), // FK a esta entidad
inverseJoinColumns = @JoinColumn(name = "etiqueta_id") // FK a la otra
)
private Set<Etiqueta> etiquetas = new HashSet<>();
// Usar Set (no List) en ManyToMany para evitar duplicados
}
@Entity
public class Etiqueta {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String nombre;
@ManyToMany(mappedBy = "etiquetas") // lado inverso — no define la tabla
private Set<Producto> productos = new HashSet<>();
}CascadeType explicado
// CascadeType define qué operaciones se propagan de padre a hijo
@OneToMany(cascade = CascadeType.ALL)
// PERSIST: al guardar el padre, guarda también los hijos
// MERGE: al actualizar el padre, actualiza también los hijos
// REMOVE: al eliminar el padre, elimina también los hijos
// REFRESH: al refrescar el padre, refresca también los hijos
// DETACH: al desconectar el padre, desconecta también los hijos
// ALL: todas las anteriores
// Uso correcto:
// Padre-hijo con dependencia total (Pedido → Items):
@OneToMany(cascade = CascadeType.ALL, orphanRemoval = true)
private List<ItemPedido> items;
// Relaciones independientes (Producto → Etiquetas):
@ManyToMany(cascade = {CascadeType.PERSIST, CascadeType.MERGE})
private Set<Etiqueta> etiquetas;
// NUNCA:
@ManyToMany(cascade = CascadeType.ALL)
// Eliminar un producto eliminaría TODAS las etiquetas compartidasFetchType: LAZY vs EAGER
// FetchType define cuándo se cargan los datos relacionados
// LAZY (default para @OneToMany, @ManyToMany):
// Los datos relacionados NO se cargan hasta que se accede a ellos
@OneToMany(fetch = FetchType.LAZY)
private List<Producto> productos;
// SQL ejecutado: SELECT * FROM categorias WHERE id = 1
// Cuando se hace categoria.getProductos():
// SQL adicional: SELECT * FROM productos WHERE categoria_id = 1
// EAGER (default para @ManyToOne, @OneToOne):
// Los datos relacionados se cargan SIEMPRE con el padre
@ManyToOne(fetch = FetchType.EAGER)
private Categoria categoria;
// SQL ejecutado: SELECT p.*, c.* FROM productos p JOIN categorias c ON p.categoria_id = c.id
// PROBLEMA CLASICO: N+1 Queries con LAZY
// Si se tienen 100 productos y se accede a categoria de cada uno:
// 1 query para los 100 productos + 100 queries para las categorías = 101 queries
// SOLUCIÓN: JOIN FETCH en la query (se vuelve algo manual)
@Query("SELECT p FROM Producto p JOIN FETCH p.categoria WHERE p.activo = true")
List<Producto> findActivosConCategoria();
// SOLUCIÓN 2: @EntityGraph
@EntityGraph(attributePaths = {"categoria", "etiquetas"})
List<Producto> findByActivoTrue();8. Herencia en JPA
// JPA soporta 3 estrategias de herencia para mapear jerarquías de clases
// SINGLE_TABLE (default): toda la jerarquía en una tabla
// Ventaja: una sola tabla, joins rápidos
// Desventaja: columnas nulas para tipos que no las usan
@Entity
@Table(name = "notificaciones")
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn(name = "tipo", discriminatorType = DiscriminatorType.STRING)
public abstract class Notificacion {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String destinatario;
private String mensaje;
private LocalDateTime enviadaEn;
}
@Entity
@DiscriminatorValue("EMAIL")
public class NotificacionEmail extends Notificacion {
@Column(name = "asunto")
private String asunto; // null para SMS y PUSH
@Column(name = "remitente")
private String remitente;
}
@Entity
@DiscriminatorValue("SMS")
public class NotificacionSMS extends Notificacion {
@Column(name = "numero_telefono")
private String numeroTelefono; // null para EMAIL y PUSH
}
// Tabla resultante:
// notificaciones(id, tipo, destinatario, mensaje, enviada_en, asunto, remitente, numero_telefono)
// tipo = "EMAIL" o "SMS"
// TABLE_PER_CLASS: tabla por clase concreta
// Ventaja: cada tabla tiene solo sus columnas
// Desventaja: queries polimórficas usan UNION (que resulta lento)
@Entity
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)
public abstract class Pago {
@Id @GeneratedValue(strategy = GenerationType.AUTO)
// TABLE_PER_CLASS requiere AUTO o SEQUENCE, no IDENTITY
private Long id;
private BigDecimal monto;
private LocalDateTime fecha;
}
@Entity
@Table(name = "pagos_tarjeta")
public class PagoTarjeta extends Pago {
private String ultimosDigitos;
private String marca; // VISA, MASTERCARD, etc.
}
@Entity
@Table(name = "pagos_transferencia")
public class PagoTransferencia extends Pago {
private String cuentaOrigen;
private String referencia;
}
// JOINED: clase base + tabla por subclase
// Ventaja: esquema en normalizado (3FN), sin columnas nulas
// Desventaja: JOIN necesario para cada consulta
@Entity
@Table(name = "empleados")
@Inheritance(strategy = InheritanceType.JOINED)
public abstract class Empleado {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String nombre;
private BigDecimal salarioBase;
}
@Entity
@Table(name = "gerentes")
@PrimaryKeyJoinColumn(name = "empleado_id")
public class Gerente extends Empleado {
private int tamanioEquipo;
private String area;
}
@Entity
@Table(name = "desarrolladores")
@PrimaryKeyJoinColumn(name = "empleado_id")
public class Desarrollador extends Empleado {
private String lenguajePrincipal;
private String nivelSeniority;
}
// SELECT e.*, d.* FROM empleados e JOIN desarrolladores d ON e.id = d.empleado_id9. REPOSITORIOS Y CONSULTAS
Crear un repositorio
// El repositorio mínimo — hereda todo de JpaRepository
@Repository // opcional con Spring Data (lo detecta automáticamente), pero es buena práctica
public interface ProductoRepository extends JpaRepository<Producto, Long> {
// Spring genera la implementación completa en tiempo de ejecución
// Ya tienes: save, findById, findAll, count, delete, exists, etc.
}
// Repositorio con tipo de ID distinto
public interface UsuarioRepository extends JpaRepository<Usuario, UUID> {}
// Repositorio de solo lectura (no expone métodos de escritura)
public interface ProductoCatalogoRepository
extends Repository<Producto, Long> {
// Solo defines los métodos de lectura que necesitas
List<Producto> findByActivoTrue();
Optional<Producto> findById(Long id);
}Los métodos que se tienen predefinidos con JpaRepository
// Al extender JpaRepository<Producto, Long> hereda:
// Guardado
Producto guardado = repo.save(producto); // insert o update (según id)
List<Producto> guardados = repo.saveAll(lista); // múltiples a la vez
Producto forzado = repo.saveAndFlush(producto); // save + flush inmediato a BD
// Búsqueda
Optional<Producto> p = repo.findById(1L); // por ID
List<Producto> todos = repo.findAll(); // todos
List<Producto> varios = repo.findAllById(ids); // por lista de IDs
boolean existe = repo.existsById(1L); // existe?
long total = repo.count(); // total de registros
// Paginación y ordenamiento
Page<Producto> pagina = repo.findAll(PageRequest.of(0, 10));
List<Producto> ordenados = repo.findAll(Sort.by("nombre").ascending());
// Eliminación
repo.deleteById(1L); // por ID
repo.delete(producto); // por entidad
repo.deleteAll(lista); // múltiples entidades
repo.deleteAll(); // TODOS
repo.deleteAllInBatch(lista); // más eficiente (una sola query)
// Flush
repo.flush(); // sincroniza el contexto JPA con la BD inmediatamente10. Derived Query Methods
Los Derived Query Methods son la característica más ágil de Spring Data: se define un método en la interfaz con un nombre específico, y Spring genera la query SQL automáticamente a partir del nombre.
La anatomía de un Derived Query Method
findBy Nombre And Precio LessThan
↑ ↑ ↑ ↑ ↑
Verbo Campo Op. Campo Condición
find...By → SELECT
count...By → SELECT COUNT
exists...By → SELECT CASE WHEN COUNT > 0...
delete...By → DELETE
Palabras clave disponibles
public interface ProductoRepository extends JpaRepository<Producto, Long> {
// Igualdad y Nulidad
List<Producto> findByNombre(String nombre);
// → WHERE nombre = ?
List<Producto> findByNombreAndActivo(String nombre, boolean activo);
// → WHERE nombre = ? AND activo = ?
List<Producto> findByNombreOrCategoriaNombre(String nombre, String catNombre);
// → WHERE p.nombre = ? OR c.nombre = ? (navega relaciones con el punto)
List<Producto> findByDescripcionIsNull();
// → WHERE descripcion IS NULL
List<Producto> findByDescripcionIsNotNull();
// → WHERE descripcion IS NOT NULL
// Comparaciones numéricas / fechas
List<Producto> findByPrecioGreaterThan(BigDecimal precio);
// → WHERE precio > ?
List<Producto> findByPrecioGreaterThanEqual(BigDecimal precio);
// → WHERE precio >= ?
List<Producto> findByPrecioLessThan(BigDecimal precio);
// → WHERE precio < ?
List<Producto> findByPrecioLessThanEqual(BigDecimal precio);
// → WHERE precio <= ?
List<Producto> findByPrecioBetween(BigDecimal min, BigDecimal max);
// → WHERE precio BETWEEN ? AND ?
List<Producto> findByFechaCreacionAfter(LocalDateTime fecha);
// → WHERE fecha_creacion > ?
List<Producto> findByFechaCreacionBefore(LocalDateTime fecha);
// → WHERE fecha_creacion < ?
List<Producto> findByFechaCreacionBetween(LocalDateTime desde, LocalDateTime hasta);
// → WHERE fecha_creacion BETWEEN ? AND ?
// Strings
List<Producto> findByNombreLike(String patron);
// → WHERE nombre LIKE ? (debes incluir % manualmente: "%laptop%")
List<Producto> findByNombreContaining(String texto);
// → WHERE nombre LIKE %?% (agrega % automáticamente)
List<Producto> findByNombreStartingWith(String prefijo);
// → WHERE nombre LIKE ?%
List<Producto> findByNombreEndingWith(String sufijo);
// → WHERE nombre LIKE %?
List<Producto> findByNombreIgnoreCase(String nombre);
// → WHERE UPPER(nombre) = UPPER(?)
List<Producto> findByNombreContainingIgnoreCase(String texto);
// → WHERE UPPER(nombre) LIKE UPPER(%?%)
// Colecciones
List<Producto> findByIdIn(List<Long> ids);
// → WHERE id IN (?, ?, ?)
List<Producto> findByIdNotIn(List<Long> ids);
// → WHERE id NOT IN (?, ?, ?)
// Booleanos
List<Producto> findByActivoTrue();
// → WHERE activo = true
List<Producto> findByActivoFalse();
// → WHERE activo = false
// Negación
List<Producto> findByNombreNot(String nombre);
// → WHERE nombre <> ?
// Navegar relaciones (con .)
List<Producto> findByCategoriaId(Long categoriaId);
// → WHERE categoria_id = ? (navega la relación @ManyToOne)
List<Producto> findByCategoriaNombre(String nombre);
// → JOIN categorias ON ... WHERE categorias.nombre = ?
List<Producto> findByCategoriaActivaTrue();
// → JOIN categorias ON ... WHERE categorias.activa = true
// Ordenamiento en el nombre
List<Producto> findByActivoTrueOrderByNombreAsc();
// → WHERE activo = true ORDER BY nombre ASC
List<Producto> findByActivoTrueOrderByPrecioDescNombreAsc();
// → WHERE activo = true ORDER BY precio DESC, nombre ASC
// ━━━ Limitar resultados ━━━
Producto findFirstByActivoTrueOrderByPrecioAsc();
// → WHERE activo = true ORDER BY precio ASC LIMIT 1
List<Producto> findTop5ByActivoTrueOrderByPrecioAsc();
// → WHERE activo = true ORDER BY precio ASC LIMIT 5
// Otras formas de retorno
Optional<Producto> findByNombre(String nombre); // Optional si puede ser null
long countByActivoTrue(); // contar
boolean existsByNombre(String nombre); // existe?
// Delete derived
void deleteByActivoFalse();
// → DELETE FROM productos WHERE activo = false
// Requiere @Transactional en el llamador
long deleteByFechaCreacionBefore(LocalDateTime fecha);
// → DELETE ... WHERE fecha_creacion < ? (retorna cuántos eliminó)
}Cuándo dejar de usar Derived Methods
// Derived methods son legibles hasta ~3 condiciones:
List<Producto> findByActivoTrueAndCategoriaNombreAndPrecioLessThan(...);
// → sostenible
// Se vuelven ilegibles con más condiciones:
List<Producto> findByActivoTrueAndCategoriaNombreAndPrecioLessThanAndStockGreaterThanAndNombreContainingIgnoreCase(...);
// → Ilegible, usa @Query en su lugar, con JPQL o SQL nativo
// Regla general: más de 3 condiciones → usar @Query11. @Query — JPQL y HQL
JPQL (Java Persistence Query Language) es el lenguaje de consultas de JPA. Es similar a SQL pero opera sobre entidades y sus campos, no sobre tablas y columnas.
Sintaxis básica de JPQL
public interface ProductoRepository extends JpaRepository<Producto, Long> {
// SELECT básico
// JPQL usa el nombre de la CLASE y sus CAMPOS (no tabla/columna)
@Query("SELECT p FROM Producto p WHERE p.activo = true")
List<Producto> findActivos();
// → SELECT * FROM productos WHERE esta_activo = true
// (Hibernate traduce p.activo al nombre de columna real)
// Con parámetros posicionales (?1, ?2...)
@Query("SELECT p FROM Producto p WHERE p.nombre = ?1 AND p.precio > ?2")
List<Producto> findByNombreYPrecio(String nombre, BigDecimal precio);
// Con parámetros nombrados (:nombre)
@Query("SELECT p FROM Producto p " +
"WHERE p.nombre LIKE %:texto% " +
"AND p.activo = :activo")
List<Producto> buscar(@Param("texto") String texto,
@Param("activo") boolean activo);
// JOIN explícito
@Query("SELECT p FROM Producto p " +
"JOIN p.categoria c " +
"WHERE c.nombre = :nombreCategoria " +
"AND p.activo = true")
List<Producto> findActivosPorCategoria(@Param("nombreCategoria") String nombre);
// JOIN FETCH — evitar N+1 queries (cargar relaciones en una sola query)
@Query("SELECT p FROM Producto p " +
"JOIN FETCH p.categoria " +
"LEFT JOIN FETCH p.etiquetas " +
"WHERE p.activo = true")
List<Producto> findActivosConRelaciones();
// Una sola query que carga producto + categoría + etiquetas
// Condiciones sobre relaciones
@Query("SELECT p FROM Producto p " +
"WHERE p.categoria.id = :catId " +
"AND p.precio BETWEEN :min AND :max " +
"ORDER BY p.precio ASC")
List<Producto> findPorCategoriaYRangoPrecio(
@Param("catId") Long catId,
@Param("min") BigDecimal min,
@Param("max") BigDecimal max
);
// Funciones en JPQL
@Query("SELECT p FROM Producto p " +
"WHERE LOWER(p.nombre) LIKE LOWER(CONCAT('%', :texto, '%'))")
List<Producto> buscarInsensible(@Param("texto") String texto);
// Contar y verificar
@Query("SELECT COUNT(p) FROM Producto p WHERE p.activo = true AND p.categoria = :cat")
long contarActivosPorCategoria(@Param("cat") Categoria categoria);
@Query("SELECT CASE WHEN COUNT(p) > 0 THEN true ELSE false END " +
"FROM Producto p WHERE p.nombre = :nombre AND p.id <> :id")
boolean existeNombreDuplicado(@Param("nombre") String nombre, @Param("id") Long id);
// Retornar campos específicos (DTO projection)
@Query("SELECT new com.ejemplo.dto.ProductoResumenDTO(p.id, p.nombre, p.precio) " +
"FROM Producto p WHERE p.activo = true ORDER BY p.nombre")
List<ProductoResumenDTO> findResumenActivos();
// El DTO debe tener un constructor que coincida
// Con IN
@Query("SELECT p FROM Producto p WHERE p.id IN :ids")
List<Producto> findByIds(@Param("ids") List<Long> ids);
// DISTINCT
@Query("SELECT DISTINCT p FROM Producto p JOIN p.etiquetas e WHERE e.nombre = :etiqueta")
List<Producto> findPorEtiqueta(@Param("etiqueta") String etiqueta);
// Subconsultas
@Query("SELECT p FROM Producto p " +
"WHERE p.precio > (SELECT AVG(p2.precio) FROM Producto p2)")
List<Producto> findSobreElPromedio();
// Con paginación — @Query es compatible con Pageable
@Query("SELECT p FROM Producto p WHERE p.activo = true ORDER BY p.nombre")
Page<Producto> findActivosPaginado(Pageable pageable);
// Con @Query + Page necesita countQuery para la query de conteo:
@Query(
value = "SELECT p FROM Producto p JOIN FETCH p.categoria WHERE p.activo = true",
countQuery = "SELECT COUNT(p) FROM Producto p WHERE p.activo = true"
)
Page<Producto> findActivosConCategoriaPaginado(Pageable pageable);
// Sin countQuery, la query principal (con JOIN FETCH) se usaría para contar
// → error porque JOIN FETCH no es válido en COUNT queries
}@Modifying — UPDATE y DELETE con @Query
public interface ProductoRepository extends JpaRepository<Producto, Long> {
// @Modifying es OBLIGATORIO para UPDATE y DELETE
// @Transactional es OBLIGATORIO (o debe estar en el llamador)
// UPDATE
@Modifying
@Transactional
@Query("UPDATE Producto p SET p.activo = false WHERE p.id = :id")
int desactivar(@Param("id") Long id);
// retorna int: número de registros afectados
@Modifying
@Transactional
@Query("UPDATE Producto p SET p.precio = p.precio * (1 - :descuento) " +
"WHERE p.categoria.id = :catId AND p.activo = true")
int aplicarDescuentoPorCategoria(@Param("catId") Long catId,
@Param("descuento") double descuento);
// DELETE
@Modifying
@Transactional
@Query("DELETE FROM Producto p WHERE p.activo = false AND p.stock = 0")
int eliminarInactivosSinStock();
// Limpiar la caché del contexto después de @Modifying
@Modifying(clearAutomatically = true) // limpia el 1er nivel de caché JPA
@Transactional
@Query("UPDATE Producto p SET p.stock = 0 WHERE p.activo = false")
int resetearStockInactivos();
// clearAutomatically = true evita que el contexto JPA tenga datos viejos
// después de un UPDATE/DELETE masivo
}12. @Query NativeQuery — SQL puro
A veces JPQL no es suficiente. Se necesita SQL puro: funciones específicas de MySQL/PostgreSQL, EXPLAIN, CTEs, window functions, etc.
public interface ProductoRepository extends JpaRepository<Producto, Long> {
// Native Query básica
@Query(value = "SELECT * FROM productos WHERE activo = 1",
nativeQuery = true)
List<Producto> findActivosNativo();
// Retorna entidades mapeadas (igual que JPQL)
// Usa nombre de TABLA y COLUMNA (no clase/campo)
// Con parámetros
@Query(value = "SELECT * FROM productos " +
"WHERE nombre LIKE CONCAT('%', :texto, '%') " +
"AND precio BETWEEN :min AND :max",
nativeQuery = true)
List<Producto> buscarNativo(@Param("texto") String texto,
@Param("min") BigDecimal min,
@Param("max") BigDecimal max);
// Funciones específicas de BD
// Ejemplo: Full Text Search de MySQL
@Query(value = "SELECT * FROM productos " +
"WHERE MATCH(nombre, descripcion) AGAINST(:texto IN BOOLEAN MODE) " +
"AND activo = 1 " +
"LIMIT :limite",
nativeQuery = true)
List<Producto> fullTextSearch(@Param("texto") String texto,
@Param("limite") int limite);
// Ejemplo: JSONB de PostgreSQL
@Query(value = "SELECT * FROM productos " +
"WHERE metadata->>'marca' = :marca",
nativeQuery = true)
List<Producto> findByMarcaJson(@Param("marca") String marca);
// Retornar solo columnas específicas con Projection
@Query(value = "SELECT id, nombre, precio FROM productos WHERE activo = 1",
nativeQuery = true)
List<ProductoResumenProjection> findResumenNativo();
// Con paginación
@Query(
value = "SELECT * FROM productos WHERE activo = 1 ORDER BY nombre",
countQuery = "SELECT COUNT(*) FROM productos WHERE activo = 1",
nativeQuery = true
)
Page<Producto> findActivosPaginadoNativo(Pageable pageable);
// countQuery es OBLIGATORIO con nativeQuery + Page
// UPDATE nativo
@Modifying
@Transactional
@Query(value = "UPDATE productos SET stock = stock - :cantidad " +
"WHERE id = :id AND stock >= :cantidad",
nativeQuery = true)
int reducirStock(@Param("id") Long id, @Param("cantidad") int cantidad);
// ━━━ Con CTE (Common Table Expressions) — PostgreSQL/SQL Server ━━━
@Query(value = """
WITH ranking AS (
SELECT id, nombre, precio,
RANK() OVER (PARTITION BY categoria_id ORDER BY precio DESC) AS rk
FROM productos
WHERE activo = 1
)
SELECT id, nombre, precio FROM ranking WHERE rk = 1
""",
nativeQuery = true)
List<ProductoMasCaro> findMasCaroPorCategoria();
// Con Window Functions — PostgreSQL
@Query(value = """
SELECT id, nombre, precio,
AVG(precio) OVER (PARTITION BY categoria_id) AS precio_promedio_categoria,
RANK() OVER (ORDER BY precio DESC) AS ranking_precio
FROM productos
WHERE activo = 1
""",
nativeQuery = true)
List<Object[]> findConEstadisticas();
// Object[] para queries que retornan columnas que no mapean a una entidad
}@SqlResultSetMapping — Mapear resultados SQL a clases
// Para native queries complejas que retornan datos de múltiples tablas:
// Definir el mapeo en la entidad
@Entity
@SqlResultSetMapping(
name = "ProductoConCategoriaMapping",
classes = @ConstructorResult(
targetClass = ProductoConCategoriaDTO.class,
columns = {
@ColumnResult(name = "id", type = Long.class),
@ColumnResult(name = "nombre"),
@ColumnResult(name = "precio", type = BigDecimal.class),
@ColumnResult(name = "categoria_nombre")
}
)
)
public class Producto { /* ... */ }
// DTO resultado
public class ProductoConCategoriaDTO {
private Long id;
private String nombre;
private BigDecimal precio;
private String categoriaNombre;
public ProductoConCategoriaDTO(Long id, String nombre,
BigDecimal precio, String categoriaNombre) {
this.id = id;
this.nombre = nombre;
this.precio = precio;
this.categoriaNombre = categoriaNombre;
}
}
// Uso con EntityManager directamente, es el responsable de hacer todo lo de JPA
@Service
public class ProductoQueryService {
@PersistenceContext
private EntityManager em;
public List<ProductoConCategoriaDTO> findConCategoria() {
return em.createNativeQuery(
"SELECT p.id, p.nombre, p.precio, c.nombre as categoria_nombre " +
"FROM productos p JOIN categorias c ON p.categoria_id = c.id",
"ProductoConCategoriaMapping"
)
.getResultList();
}
}13. Projections — Traer solo lo que se necesita
Una Projection permite retornar un subconjunto de campos de una entidad, evitando traer datos innecesarios de la BD.
Interface Projections (cerradas)
// Definir la projection como interfaz
// Spring Data genera la implementación automáticamente (proxy)
public interface ProductoResumen {
Long getId();
String getNombre();
BigDecimal getPrecio();
// Solo estos 3 campos — Hibernate genera: SELECT id, nombre, precio FROM ...
}
// Projection con campo calculado (SpEL)
public interface ProductoConDescuento {
Long getId();
String getNombre();
BigDecimal getPrecio();
@Value("#{target.precio * 0.9}") // SpEL: accede al objeto original con target
BigDecimal getPrecioConDescuento();
@Value("#{target.nombre + ' (' + target.categoria.nombre + ')'}")
String getNombreCompleto();
}
// Uso en repositorio:
public interface ProductoRepository extends JpaRepository<Producto, Long> {
// Spring Data genera el SELECT apropiado basado en los métodos de la projection
List<ProductoResumen> findByActivoTrue();
// → SELECT id, nombre, precio FROM productos WHERE activo = true
Optional<ProductoResumen> findResumenById(Long id);
// Con @Query también funciona:
@Query("SELECT p FROM Producto p WHERE p.precio > :min")
List<ProductoResumen> findResumenPorPrecioMinimo(@Param("min") BigDecimal min);
}Interface Projections (abiertas) — con lógica calculada
public interface ResumenPedido {
String getNumeroPedido();
String getClienteNombre();
// @Value permite computar campos a partir de los datos cargados
@Value("#{target.items.stream().mapToDouble(i -> i.precio * i.cantidad).sum()}")
double getTotal();
@Value("#{target.items.size()}")
int getCantidadItems();
}Class-based Projections (DTO Record Projections)
// A partir de Spring Data 3 / Hibernate 6, se puede usar Records directamente:
record ProductoResumenDTO(Long id, String nombre, BigDecimal precio) {}
// En el repositorio:
public interface ProductoRepository extends JpaRepository<Producto, Long> {
// Con Derived Method:
List<ProductoResumenDTO> findByActivoTrue();
// Con @Query (constructor expression en JPQL):
@Query("SELECT new com.ejemplo.dto.ProductoResumenDTO(p.id, p.nombre, p.precio) " +
"FROM Producto p WHERE p.activo = true")
List<ProductoResumenDTO> findResumenActivos();
}Dynamic Projections — elegir la projection en tiempo de ejecución
// Un solo método que puede retornar distintas projections
public interface ProductoRepository extends JpaRepository<Producto, Long> {
<T> List<T> findByActivoTrue(Class<T> type);
<T> Optional<T> findById(Long id, Class<T> type);
}
// Uso en servicio:
List<ProductoResumen> resumenes = repo.findByActivoTrue(ProductoResumen.class);
List<Producto> completos = repo.findByActivoTrue(Producto.class); // entidad completa
List<ProductoResumenDTO> dtos = repo.findByActivoTrue(ProductoResumenDTO.class);14. Paginación y Ordenamiento
Pageable — el objeto mágico
// Crear un Pageable
Pageable primerosPagina = PageRequest.of(0, 10);
// página 0 (primera), 10 elementos por página
Pageable conOrden = PageRequest.of(0, 10, Sort.by("nombre").ascending());
Pageable ordenMultiple = PageRequest.of(0, 20,
Sort.by(Sort.Direction.DESC, "precio")
.and(Sort.by(Sort.Direction.ASC, "nombre"))
);
// En el repositorio
public interface ProductoRepository extends JpaRepository<Producto, Long> {
// Pageable como parámetro:
Page<Producto> findByActivoTrue(Pageable pageable);
Page<Producto> findByCategoriaNombre(String nombre, Pageable pageable);
// Slice: como Page pero sin contar el total (más rápido para infinite scroll)
Slice<Producto> findByPrecioLessThan(BigDecimal precio, Pageable pageable);
}Usar Pageable desde un Controller REST
@RestController
@RequestMapping("/api/productos")
@RequiredArgsConstructor
public class ProductoController {
private final ProductoRepository repo;
// Recibir parámetros de paginación en la URL:
// GET /api/productos?page=0&size=10&sort=nombre,asc&sort=precio,desc
@GetMapping
public Page<Producto> listar(
@RequestParam(defaultValue = "0") int page,
@RequestParam(defaultValue = "10") int size,
@RequestParam(defaultValue = "nombre") String sortBy,
@RequestParam(defaultValue = "asc") String direction
) {
Sort sort = direction.equalsIgnoreCase("desc")
? Sort.by(sortBy).descending()
: Sort.by(sortBy).ascending();
Pageable pageable = PageRequest.of(page, size, sort);
return repo.findByActivoTrue(pageable);
}
// Usando @PageableDefault de Spring
@GetMapping("/v2")
public Page<Producto> listarV2(
@PageableDefault(size = 10, sort = "nombre", direction = Sort.Direction.ASC)
Pageable pageable
) {
return repo.findByActivoTrue(pageable);
}
}El objeto Page
// Page<T> contiene:
Page<Producto> pagina = repo.findByActivoTrue(PageRequest.of(0, 10));
pagina.getContent(); // List<Producto> — los datos de esta página
pagina.getNumber(); // int — número de página actual (0-indexed)
pagina.getSize(); // int — tamaño de página
pagina.getTotalElements(); // long — total de registros en BD
pagina.getTotalPages(); // int — total de páginas
pagina.isFirst(); // boolean
pagina.isLast(); // boolean
pagina.hasNext(); // boolean
pagina.hasPrevious(); // boolean
pagina.nextPageable(); // Pageable para la siguiente página
pagina.previousPageable(); // Pageable para la página anterior
// Para retornar una respuesta limpia sin exponer Page<T> directamente:
record PaginaResponse<T>(
List<T> contenido,
int pagina,
int totalPaginas,
long totalElementos,
boolean esUltima
) {
static <T> PaginaResponse<T> from(Page<T> page) {
return new PaginaResponse<>(
page.getContent(), page.getNumber(),
page.getTotalPages(), page.getTotalElements(), page.isLast()
);
}
}Sort — Ordenamiento flexible
// Crear Sort objects:
Sort simple = Sort.by("nombre");
Sort desc = Sort.by(Sort.Direction.DESC, "precio");
Sort multiple = Sort.by("activo").descending()
.and(Sort.by("precio").ascending());
// Sort desde strings (útil para parámetros de URL):
Sort fromString = Sort.by(Sort.Order.asc("nombre"), Sort.Order.desc("precio"));
// En el repositorio:
public interface ProductoRepository extends JpaRepository<Producto, Long> {
List<Producto> findByActivoTrue(Sort sort);
}
// En el servicio:
Sort sort = Sort.by("precio").descending();
List<Producto> productos = repo.findByActivoTrue(sort);15. Specifications — Consultas dinámicas
Las Specifications son la solución de Spring Data para construir queries dinámicas (filtros que el usuario puede activar o no), por ejemplo, cuando creamos un ecommerce. Implementan el patrón Specification del libro DDD de Eric Evans.
Configurar Specifications
<!-- Requiere JpaSpecificationExecutor -->// El repositorio debe extender JpaSpecificationExecutor
public interface ProductoRepository extends JpaRepository<Producto, Long>,
JpaSpecificationExecutor<Producto> {
// JpaSpecificationExecutor agrega:
// findOne(Specification)
// findAll(Specification)
// findAll(Specification, Pageable)
// findAll(Specification, Sort)
// count(Specification)
}Crear Specifications
// Una Specification es básicamente una función que construye un Predicate JPA Criteria
// Forma 1: como lambdas (más concisa)
public class ProductoSpecs {
public static Specification<Producto> activo() {
return (root, query, cb) -> cb.isTrue(root.get("activo"));
// ↑ ↑ ↑
// Root CriteriaQuery CriteriaBuilder
// root = FROM producto p
// cb = constructor de predicados (WHERE, AND, OR, etc.)
}
public static Specification<Producto> conNombre(String texto) {
return (root, query, cb) -> {
if (texto == null || texto.isBlank()) return null; // null = sin filtro
return cb.like(cb.lower(root.get("nombre")),
"%" + texto.toLowerCase() + "%");
};
}
public static Specification<Producto> conPrecioEntre(BigDecimal min, BigDecimal max) {
return (root, query, cb) -> {
if (min == null && max == null) return null;
if (min == null) return cb.lessThanOrEqualTo(root.get("precio"), max);
if (max == null) return cb.greaterThanOrEqualTo(root.get("precio"), min);
return cb.between(root.get("precio"), min, max);
};
}
public static Specification<Producto> enCategoria(Long categoriaId) {
return (root, query, cb) -> {
if (categoriaId == null) return null;
// Navegar relación @ManyToOne
Join<Producto, Categoria> categoria = root.join("categoria", JoinType.INNER);
return cb.equal(categoria.get("id"), categoriaId);
};
}
public static Specification<Producto> conStockMinimo(Integer stockMin) {
return (root, query, cb) -> {
if (stockMin == null) return null;
return cb.greaterThanOrEqualTo(root.get("stock"), stockMin);
};
}
// Con etiquetas (relación @ManyToMany)
public static Specification<Producto> conEtiqueta(String etiqueta) {
return (root, query, cb) -> {
if (etiqueta == null) return null;
query.distinct(true); // evitar duplicados por el JOIN
Join<Producto, Etiqueta> etiquetas = root.join("etiquetas", JoinType.LEFT);
return cb.equal(etiquetas.get("nombre"), etiqueta);
};
}
}Combinar Specifications
// Las Specifications se combinan con .and(), .or(), .not()
@Service
@RequiredArgsConstructor
public class ProductoBuscadorService {
private final ProductoRepository repo;
public Page<Producto> buscar(FiltroBusquedaDTO filtro, Pageable pageable) {
// Construir specification dinámicamente
Specification<Producto> spec = Specification.where(ProductoSpecs.activo());
if (filtro.getNombre() != null) {
spec = spec.and(ProductoSpecs.conNombre(filtro.getNombre()));
}
if (filtro.getCategoriaId() != null) {
spec = spec.and(ProductoSpecs.enCategoria(filtro.getCategoriaId()));
}
if (filtro.getPrecioMin() != null || filtro.getPrecioMax() != null) {
spec = spec.and(ProductoSpecs.conPrecioEntre(
filtro.getPrecioMin(), filtro.getPrecioMax()));
}
if (filtro.getStockMinimo() != null) {
spec = spec.and(ProductoSpecs.conStockMinimo(filtro.getStockMinimo()));
}
return repo.findAll(spec, pageable);
}
// Ejemplo con OR:
public List<Producto> buscarEnRango(BigDecimal min1, BigDecimal max1,
BigDecimal min2, BigDecimal max2) {
Specification<Producto> rango1 = ProductoSpecs.conPrecioEntre(min1, max1);
Specification<Producto> rango2 = ProductoSpecs.conPrecioEntre(min2, max2);
return repo.findAll(rango1.or(rango2));
}
// NOT:
public List<Producto> findNoActivos() {
return repo.findAll(Specification.not(ProductoSpecs.activo()));
}
}Controller con búsqueda dinámica
@RestController
@RequestMapping("/api/productos")
@RequiredArgsConstructor
public class ProductoController {
private final ProductoBuscadorService buscador;
// GET /api/productos/buscar?nombre=lap&categoriaId=2&precioMin=100&precioMax=2000
@GetMapping("/buscar")
public Page<Producto> buscar(
@RequestParam(required = false) String nombre,
@RequestParam(required = false) Long categoriaId,
@RequestParam(required = false) BigDecimal precioMin,
@RequestParam(required = false) BigDecimal precioMax,
@RequestParam(required = false) Integer stockMinimo,
@PageableDefault(size = 20, sort = "nombre") Pageable pageable
) {
FiltroBusquedaDTO filtro = new FiltroBusquedaDTO(
nombre, categoriaId, precioMin, precioMax, stockMinimo);
return buscador.buscar(filtro, pageable);
}
}16. QueryDSL
QueryDSL es una librería que genera clases “Q” en tiempo de compilación para hacer queries type-safe y con autocompletado del IDE. Es una alternativa más potente que Specifications para consultas complejas.
Configurar QueryDSL
<dependency>
<groupId>com.querydsl</groupId>
<artifactId>querydsl-jpa</artifactId>
<classifier>jakarta</classifier>
</dependency>
<dependency>
<groupId>com.querydsl</groupId>
<artifactId>querydsl-apt</artifactId>
<classifier>jakarta</classifier>
<scope>provided</scope>
</dependency>
<build>
<plugins>
<plugin>
<groupId>com.mysema.maven</groupId>
<artifactId>apt-maven-plugin</artifactId>
<version>1.1.3</version>
<executions>
<execution>
<goals><goal>process</goal></goals>
<configuration>
<outputDirectory>target/generated-sources/java</outputDirectory>
<processor>com.querydsl.apt.jpa.JPAAnnotationProcessor</processor>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>// El repositorio extiende QuerydslPredicateExecutor
public interface ProductoRepository extends JpaRepository<Producto, Long>,
QuerydslPredicateExecutor<Producto> {}
// Uso — QueryDSL genera la clase QProducto con todos los campos tipados:
@Service
@RequiredArgsConstructor
public class ProductoQueryDSLService {
private final ProductoRepository repo;
public List<Producto> buscar(String nombre, BigDecimal precioMax) {
QProducto p = QProducto.producto; // clase generada automáticamente
BooleanBuilder builder = new BooleanBuilder();
if (nombre != null) {
builder.and(p.nombre.containsIgnoreCase(nombre));
}
if (precioMax != null) {
builder.and(p.precio.loe(precioMax)); // loe = less or equal
}
builder.and(p.activo.isTrue());
return (List<Producto>) repo.findAll(builder);
}
}17. Spring Data JDBC en detalle
Spring Data JDBC es una alternativa más simple a JPA. No tiene LazyLoading, caché de primer nivel, ni entidades “managed”. Todo es explícito.
Configurar Spring Data JDBC
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jdbc</artifactId>
</dependency>Entidades en Spring Data JDBC
// En Spring Data JDBC las entidades son POJOs simples
// Sin @Entity, sin @ManyToOne, sin CascadeType — todo es explícito
import org.springframework.data.annotation.Id;
import org.springframework.data.relational.core.mapping.Table;
import org.springframework.data.relational.core.mapping.Column;
@Table("productos") // de spring-data-relational (no de JPA)
public class Producto {
@Id // de spring-data (no de JPA)
private Long id;
private String nombre;
private BigDecimal precio;
@Column("esta_activo")
private boolean activo;
// Las relaciones se modelan como AGREGADOS (DDD)
// Los objetos hijos se guardan/eliminan con el padre automáticamente
private Set<ItemProducto> imagenes = new HashSet<>();
// Spring Data JDBC asume que imagenes tiene una FK a productos
}
// Objeto embebido (no tiene tabla propia):
public class Imagenes {
private String url;
private String tipo; // "thumbnail", "full", etc.
}Repositorio Spring Data JDBC
public interface ProductoJdbcRepository extends CrudRepository<Producto, Long> {
// Derived methods funcionan igual que en JPA
List<Producto> findByActivoTrue();
List<Producto> findByNombreContainingIgnoreCase(String texto);
// @Query con SQL nativo (JDBC usa SQL directamente, no JPQL)
@Query("SELECT * FROM productos WHERE precio BETWEEN :min AND :max ORDER BY precio")
List<Producto> findPorRangoPrecio(@Param("min") BigDecimal min,
@Param("max") BigDecimal max);
@Modifying
@Query("UPDATE productos SET activo = false WHERE id = :id")
void desactivar(@Param("id") Long id);
}18. JdbcTemplate — SQL directo
JdbcTemplate es la forma más básica de usar JDBC en Spring. Da control total del SQL sin ORM. Ideal cuando necesitas queries muy específicas o tienes lógica compleja que JPA no maneja bien.
@Repository
@RequiredArgsConstructor
public class ProductoJdbcRepository {
private final JdbcTemplate jdbc;
// queryForObject — retorna un solo valor
public int contarActivos() {
return jdbc.queryForObject(
"SELECT COUNT(*) FROM productos WHERE activo = 1",
Integer.class
);
}
public BigDecimal obtenerPrecioPromedio() {
return jdbc.queryForObject(
"SELECT AVG(precio) FROM productos WHERE activo = 1",
BigDecimal.class
);
}
// queryForObject — retorna un objeto mapeado
public Producto findById(Long id) {
try {
return jdbc.queryForObject(
"SELECT * FROM productos WHERE id = ?",
productoRowMapper(),
id
);
} catch (EmptyResultDataAccessException e) {
return null; // o lanzar excepción
}
}
// query — retorna una lista
public List<Producto> findActivos() {
return jdbc.query(
"SELECT * FROM productos WHERE activo = 1 ORDER BY nombre",
productoRowMapper()
);
}
public List<Producto> findPorCategoria(Long categoriaId) {
return jdbc.query(
"SELECT * FROM productos WHERE categoria_id = ? AND activo = 1",
productoRowMapper(),
categoriaId // parámetros adicionales del varargs
);
}
// RowMapper — define cómo mapear ResultSet → objeto
private RowMapper<Producto> productoRowMapper() {
return (rs, rowNum) -> {
Producto p = new Producto();
p.setId(rs.getLong("id"));
p.setNombre(rs.getString("nombre"));
p.setPrecio(rs.getBigDecimal("precio"));
p.setActivo(rs.getBoolean("activo"));
// rs.getTimestamp("fecha_creacion").toLocalDateTime()
return p;
};
}
// BeanPropertyRowMapper — mapeo automático por nombre de columna
public List<Producto> findTodos() {
return jdbc.query(
"SELECT * FROM productos",
new BeanPropertyRowMapper<>(Producto.class)
// Mapea columna_nombre → setColumnNombre() automáticamente
// Funciona si los nombres coinciden (underscore → camelCase)
);
}
// update — INSERT, UPDATE, DELETE
public int actualizar(Long id, String nombre, BigDecimal precio) {
return jdbc.update(
"UPDATE productos SET nombre = ?, precio = ? WHERE id = ?",
nombre, precio, id
);
}
// INSERT retornando la clave generada:
public Long insertar(String nombre, BigDecimal precio) {
KeyHolder keyHolder = new GeneratedKeyHolder();
jdbc.update(connection -> {
PreparedStatement ps = connection.prepareStatement(
"INSERT INTO productos (nombre, precio, activo) VALUES (?, ?, 1)",
Statement.RETURN_GENERATED_KEYS
);
ps.setString(1, nombre);
ps.setBigDecimal(2, precio);
return ps;
}, keyHolder);
return keyHolder.getKey().longValue();
}
// batchUpdate — operaciones masivas
public int[] insertarLote(List<Producto> productos) {
return jdbc.batchUpdate(
"INSERT INTO productos (nombre, precio, activo) VALUES (?, ?, ?)",
productos,
100, // tamaño del lote
(ps, p) -> {
ps.setString(1, p.getNombre());
ps.setBigDecimal(2, p.getPrecio());
ps.setBoolean(3, true);
}
);
}
// NamedParameterJdbcTemplate — parámetros nombrados
@Autowired
private NamedParameterJdbcTemplate namedJdbc;
public List<Producto> buscarConNombrados(String nombre, BigDecimal precioMax) {
Map<String, Object> params = new HashMap<>();
params.put("nombre", "%" + nombre + "%");
params.put("precioMax", precioMax);
return namedJdbc.query(
"SELECT * FROM productos WHERE nombre LIKE :nombre AND precio <= :precioMax",
params,
productoRowMapper()
);
}
// Con SqlParameterSource (más elegante):
public Producto buscarUno(Long id) {
MapSqlParameterSource params = new MapSqlParameterSource()
.addValue("id", id);
return namedJdbc.queryForObject(
"SELECT * FROM productos WHERE id = :id",
params,
productoRowMapper()
);
}
}19. Transacciones en Spring Data
@Transactional
// @Transactional de Spring Data
@Service
public class PedidoService {
// Básico
@Transactional // REQUIRED por defecto: usa tx existente o crea una nueva
public Pedido crear(CrearPedidoRequest request) {
// Todo aquí está dentro de una transacción
Pedido pedido = pedidoRepo.save(new Pedido(request));
inventarioService.reservar(request.items()); // también transaccional
emailService.enviarConfirmacion(pedido); // NO transaccional
return pedido;
// Si lanza RuntimeException → ROLLBACK automático
// Si todo sale bien → COMMIT
}
// readOnly — optimización para consultas
@Transactional(readOnly = true)
// Hibernate: no rastrea cambios (dirty checking desactivado)
// BD: puede usar réplicas de lectura
// Más eficiente para consultas que no modifican datos
public List<Pedido> listar() {
return pedidoRepo.findAll();
}
// Propagation — comportamiento con transacciones existentes
@Transactional(propagation = Propagation.REQUIRED)
// REQUIRED (default): usa la tx actual si existe, crea una si no
// Si el llamador tiene tx → participa en ella
public void operar() { }
@Transactional(propagation = Propagation.REQUIRES_NEW)
// Siempre crea una nueva tx, suspende la actual
// Se commitea/rollbackea de forma independiente
// Útil para: logs de auditoría, métricas (deben persistir aunque falle lo demás)
public void auditarOperacion(String descripcion) {
auditoria.save(new Auditoria(descripcion));
// si el llamador hace rollback, este registro PERMANECE en BD
}
@Transactional(propagation = Propagation.NESTED)
// Crea un savepoint dentro de la tx actual
// Si esta falla, el rollback es solo hasta el savepoint
// Útil para operaciones que pueden fallar sin afectar el todo
public void intentarOperacionRiesgosa() { }
@Transactional(propagation = Propagation.SUPPORTS)
// Si hay tx activa → participa. Si no → ejecuta sin tx
public void operacionOpcionalmenteTransaccional() { }
@Transactional(propagation = Propagation.NOT_SUPPORTED)
// Suspende la tx actual y ejecuta sin transacción
public void operacionSinTransaccion() { }
@Transactional(propagation = Propagation.MANDATORY)
// DEBE haber una tx activa, si no → excepción
public void requiereTxExterna() { }
@Transactional(propagation = Propagation.NEVER)
// Si hay tx activa → excepción
public void noDebeEstarEnTx() { }
// rollbackFor — controlar cuándo hacer rollback
@Transactional(rollbackFor = Exception.class)
// Por defecto solo hace rollback con RuntimeException y Error
// rollbackFor = Exception.class → también con checked exceptions
public void guardarConCheckedException() throws IOException { }
@Transactional(noRollbackFor = InventarioInsuficienteException.class)
// No hace rollback para esta excepción específica
public void procesarConExcepcionManejada() { }
// timeout — cancelar tx si tarda demasiado
@Transactional(timeout = 30) // rollback si supera 30 segundos
public void operacionLenta() { }
// isolation — nivel de aislamiento
@Transactional(isolation = Isolation.READ_COMMITTED)
// DEFAULT: el de la BD
// READ_UNCOMMITTED: lee datos sin commitear (dirty reads)
// READ_COMMITTED: solo lee datos commiteados (default MySQL/PostgreSQL)
// REPEATABLE_READ: misma lectura = mismo resultado durante la tx
// SERIALIZABLE: máximo aislamiento (más lento)
public void operacionAislada() { }
}Transacciones en repositorios
// Los métodos de JpaRepository ya tienen @Transactional configurado:
// save(), delete() → @Transactional (escritura)
// findById(), findAll() → @Transactional(readOnly = true)
// Puedes sobrescribir en tu repositorio:
public interface ProductoRepository extends JpaRepository<Producto, Long> {
// Hacer que un método heredado sea readOnly:
@Override
@Transactional(readOnly = true)
List<Producto> findAll();
// Agregar @Transactional a un derived method que modifica:
@Transactional
void deleteByActivoFalse();
}20. Auditoría automática
Spring Data puede poblar automáticamente campos de auditoría: quién creó/modificó y cuándo.
Configurar la Auditoría
// 1. Habilitar la auditoría
@Configuration
@EnableJpaAuditing(auditorAwareRef = "auditorProvider")
public class AuditoriaConfig {
// Spring usa este bean para saber "quién" está haciendo la operación
@Bean
public AuditorAware<String> auditorProvider() {
// Obtener el usuario del contexto de seguridad (Spring Security)
return () -> {
Authentication auth = SecurityContextHolder.getContext().getAuthentication();
if (auth == null || !auth.isAuthenticated()) {
return Optional.of("sistema");
}
return Optional.of(auth.getName());
};
}
}// 2. Clase base para entidades auditables (reutilizable)
@MappedSuperclass // no crea tabla, sus campos se heredan en las subclases
@EntityListeners(AuditingEntityListener.class) // habilita la auditoría JPA
public abstract class EntidadAuditable {
@CreatedDate
@Column(name = "creado_en", updatable = false)
private LocalDateTime creadoEn;
@LastModifiedDate
@Column(name = "actualizado_en")
private LocalDateTime actualizadoEn;
@CreatedBy
@Column(name = "creado_por", updatable = false, length = 100)
private String creadoPor;
@LastModifiedBy
@Column(name = "actualizado_por", length = 100)
private String actualizadoPor;
// getters...
}
// 3. Extender en tus entidades
@Entity
@Table(name = "productos")
public class Producto extends EntidadAuditable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String nombre;
private BigDecimal precio;
// Spring Data llenará automáticamente:
// creado_en → fecha al INSERT
// actualizado_en → fecha al INSERT y UPDATE
// creado_por → usuario actual al INSERT
// actualizado_por → usuario actual al INSERT y UPDATE
}@Version — Control de concurrencia optimista
@Entity
public class Inventario {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private Long productoId;
private int cantidad;
@Version // Hibernate gestiona este campo automáticamente
private Long version;
// Al UPDATE: WHERE id = ? AND version = ? → incrementa version
// Si otro hilo modificó el registro (version cambió) → OptimisticLockException
}
// Ejemplo de flujo:
// Hilo A lee Inventario{id=1, cantidad=10, version=3}
// Hilo B lee Inventario{id=1, cantidad=10, version=3}
// Hilo A actualiza → UPDATE ... WHERE id=1 AND version=3 → OK, version=4
// Hilo B intenta actualizar → UPDATE ... WHERE id=1 AND version=3 → FALLA (version=4 ahora)
// → lanza OptimisticLockException
// Manejar el conflicto:
@Service
public class InventarioService {
@Retryable(value = OptimisticLockingFailureException.class, maxAttempts = 3)
@Transactional
public void reducirStock(Long productoId, int cantidad) {
Inventario inv = repo.findByProductoId(productoId).orElseThrow();
if (inv.getCantidad() < cantidad) throw new StockInsuficienteException();
inv.setCantidad(inv.getCantidad() - cantidad);
repo.save(inv); // si hay conflicto → OptimisticLockException → @Retryable reintenta
}
}Tabla resumen de consultas
| Técnica | Configuración | Cuándo |
|---|---|---|
| Derived Methods | Solo el nombre del método | CRUD simple, ≤3 condiciones |
@Query JPQL | @Query("SELECT p FROM Producto...") | Queries con lógica, JOIN FETCH |
@Query Native | @Query(value="SELECT...", nativeQuery=true) | SQL específico de BD |
| Specifications | extends JpaSpecificationExecutor | Filtros dinámicos |
| QueryDSL | Dependencia extra + clases Q | Filtros muy complejos, type-safe |
| Projections | Interface/Record con campos | Traer solo columnas necesarias |
| Pageable | Page<T> findAll(Pageable) | Paginación y ordenamiento |
| JdbcTemplate | @Autowired JdbcTemplate | SQL manual, queries masivas |
| EntityManager | @PersistenceContext EntityManager | Criteria API, control total JPA |
📚 Recursos para profundizar:
- Spring Data JPA Reference Documentation → docs.spring.io/spring-data/jpa
- Hibernate User Guide → hibernate.org/orm/documentation
- Spring Data — Mark Paluch, Christoph Strobl (libro oficial del proyecto)
- Vlad Mihalcea Blog → vladmihalcea.com (el recurso más completo sobre Hibernate avanzado)
- Baeldung → Spring Data JPA Tutorial Series